PRISM – Ablation
Relative Präferenz
In dieser Ablationsstudie wird das zentrale Element von PRISM – die Relative Präferenz – detailliert untersucht. Hierzu wurden drei Modellvarianten trainiert:
- Baseline: Ein Modell ohne PRISM.
- PRISM ohne Relative Präferenz: Ein Modell, das die Multi-Uni Self-Distillation verwendet, jedoch ohne den zusätzlichen Mechanismus der relativen Präferenz.
- PRISM (vollständig): Das vollständige PRISM-Modell, das sowohl die Self-Distillation als auch die relative Präferenz implementiert.
Während des gesamten Trainings werden sogenannte Präferenzkurven aufgezeichnet. Diese Kurven zeigen, wie ausgewogen die verschiedenen Modalitäten im Lernprozess integriert werden – je näher die Kurve an 0 liegt, desto besser sind die Modalitäten ausbalanciert. Unsere Ergebnisse deuten darauf hin, dass Modelle, die lediglich auf der Multi-Uni Self-Distillation basieren, nur eine marginale Balance der Modalitäten erreichen. Erst der zusätzliche Einsatz der relativen Präferenz führt zu einer signifikanten Harmonisierung, wodurch alle Modalitäten gleichmäßiger im Training berücksichtigt werden.
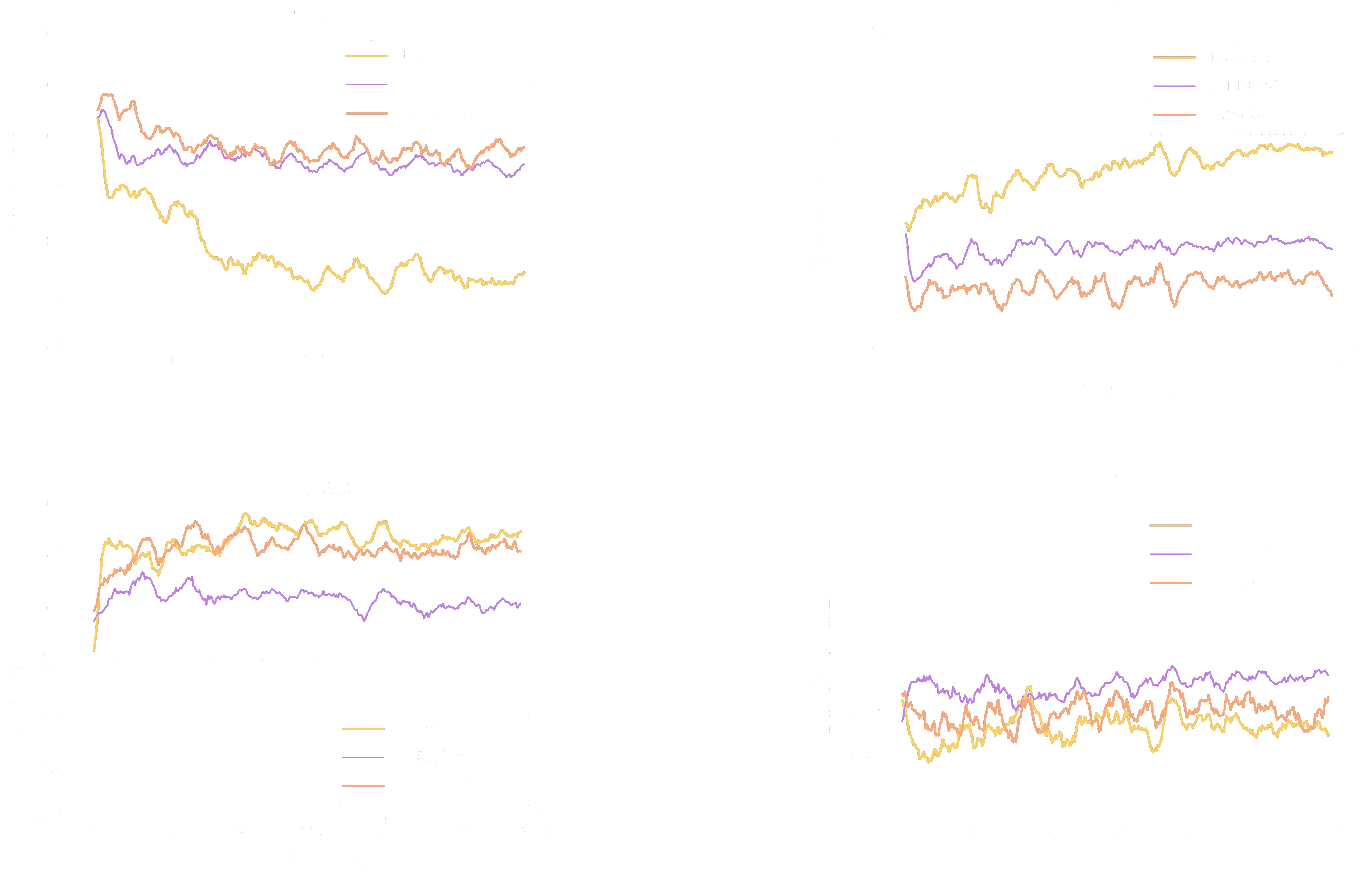
Komponentenablation
| Komponenten | BraTS2020 FR=(0.2, 0.4, 0.6, 0.8) | MyoPS2020 FR=(0.3,0.5,0.7) | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DICE [%] ↑ | HD [mm] ↓ | DICE [%] ↑ | HD [mm] ↓ | ||||||||||||||||
| Lpixel | Lproto | ω | E | WT | TC | ET | Avg. | WT | TC | ET | Avg. | LVB | RVB | MYO | Avg. | LVB | RVB | MYO | Avg. |
| ○ | ○ | ○ | ○ | 78.12 | 66.35 | 48.28 | 64.25 | 29.15 | 24.40 | 15.08 | 22.88 | 75.90 | 55.05 | 69.70 | 66.88 | 21.40 | 24.70 | 23.25 | 23.12 |
| ● | ○ | ○ | ○ | 84.75 | 71.55 | 52.78 | 69.69 | 12.58 | 12.65 | 9.40 | 11.54 | 81.80 | 54.70 | 78.10 | 71.53 | 14.35 | 28.75 | 18.55 | 20.55 |
| ○ | ● | ○ | ○ | 83.25 | 71.05 | 53.22 | 69.17 | 20.05 | 19.20 | 12.05 | 17.10 | 79.80 | 58.30 | 75.05 | 71.05 | 16.50 | 27.80 | 17.20 | 20.50 |
| ● | ● | ○ | ○ | 85.50 | 72.40 | 54.20 | 70.70 | 11.55 | 12.80 | 8.30 | 10.88 | 82.90 | 59.75 | 79.00 | 73.88 | 11.80 | 24.70 | 12.10 | 16.20 |
| ● | ● | ● | ○ | 86.80 | 74.00 | 55.10 | 71.97 | 10.50 | 10.80 | 7.30 | 9.53 | 83.60 | 62.65 | 79.30 | 75.18 | 11.30 | 19.55 | 11.25 | 14.03 |
| ● | ● | ● | ● | 87.95 | 75.20 | 56.80 | 73.32 | 8.90 | 8.80 | 5.40 | 7.70 | 85.50 | 65.00 | 81.40 | 77.30 | 8.35 | 17.50 | 8.70 | 11.52 |
Die Ergebnisse der Ablationsstudie auf den Datensätzen BraTS2020 und MyoPS2020 zeigen deutlich, dass die getrennte Einführung jeder einzelnen Komponente vorteilhaft ist. Die direkte Kombination aus pixelweiser und semantisch basierter Distillation führt zwar zu marginalen Verbesserungen, jedoch nur, wenn keine zusätzlichen Regularisierungsmaßnahmen angewendet werden. Hingegen erzielt die simultane Einführung aller Komponenten – also die Integration der Self-Distillation (sowohl auf Pixel- als auch auf Semantikebene) in Kombination mit der präferenzbasierten Regularisierung – die besten Ergebnisse. Diese umfassende Strategie ermöglicht es, sowohl lokale als auch globale Informationen optimal zu nutzen und sorgt für ein ausgewogenes Training über alle Modalitäten hinweg.
Evaluierung von PRISM als Plug-and-Play-Modul
| Typ | Szenario | T1 | ● | ○ | ○ | ○ | ● | ● | ● | ○ | ○ | ○ | ● | ● | ● | ○ | ● | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T1ce | ○ | ● | ○ | ○ | ● | ○ | ○ | ● | ● | ○ | ● | ● | ○ | ● | ● | |||
| Flair | ○ | ○ | ● | ○ | ○ | ● | ○ | ● | ○ | ● | ● | ○ | ● | ● | ● | |||
| T2 | ○ | ○ | ○ | ● | ○ | ○ | ● | ○ | ● | ● | ● | ○ | ● | ● | ● | |||
| WT | VTD | RFNet [1] | 68.53 | 69.27 | 82.28 | 82.25 | 74.07 | 85.51 | 84.90 | 85.18 | 83.94 | 86.42 | 86.61 | 85.40 | 87.63 | 87.36 | 88.30 | 82.51 |
| mmFormer [2] | 69.60 | 69.87 | 83.34 | 83.33 | 74.74 | 86.60 | 85.81 | 87.39 | 85.47 | 87.73 | 87.99 | 86.40 | 88.60 | 88.84 | 89.27 | 83.67 | ||
| PRISMS | 77.89 | 78.69 | 87.62 | 86.54 | 81.70 | 89.12 | 87.04 | 89.71 | 88.47 | 89.57 | 90.75 | 89.42 | 90.68 | 89.31 | 88.57 | 87.01 | ||
| UTD | RFNet [1] | 69.46 | 69.95 | 78.79 | 72.82 | 75.82 | 85.04 | 78.77 | 84.12 | 77.89 | 83.16 | 86.23 | 81.95 | 86.25 | 85.00 | 86.85 | 80.14 | |
| mmFormer [2] | 65.93 | 68.07 | 78.10 | 72.16 | 76.40 | 83.60 | 81.71 | 83.86 | 78.17 | 83.24 | 86.39 | 84.28 | 85.98 | 85.23 | 87.36 | 80.03 | ||
| PRISMS | 70.85 | 71.70 | 80.27 | 73.40 | 76.79 | 85.12 | 82.80 | 84.08 | 79.15 | 83.92 | 87.39 | 84.82 | 86.56 | 86.40 | 87.50 | 81.38 | ||
| UTD (+PRISM) | RFNet [1] | 72.20 | 75.02 | 83.95 | 81.35 | 76.45 | 86.78 | 82.38 | 85.57 | 82.60 | 86.85 | 87.46 | 83.04 | 87.91 | 87.45 | 88.20 | 83.15 | |
| mmFormer [2] | 71.78 | 73.73 | 84.37 | 82.27 | 77.93 | 86.93 | 84.05 | 87.14 | 84.78 | 86.85 | 88.07 | 85.88 | 87.58 | 88.44 | 88.88 | 83.91 | ||
| PRISMS | 77.00 | 78.22 | 88.27 | 84.58 | 80.09 | 90.79 | 85.58 | 89.66 | 87.38 | 89.98 | 90.78 | 87.19 | 89.49 | 90.66 | 86.05 | 86.38 | ||
| TC | VTD | RFNet [1] | 59.53 | 77.24 | 64.30 | 66.77 | 81.45 | 70.28 | 70.39 | 80.16 | 81.90 | 70.70 | 81.67 | 83.28 | 72.83 | 81.97 | 82.80 | 75.02 |
| mmFormer [2] | 56.00 | 76.40 | 61.74 | 63.74 | 80.50 | 67.07 | 66.61 | 79.67 | 81.36 | 68.66 | 80.71 | 82.23 | 69.89 | 81.25 | 81.90 | 73.18 | ||
| PRISMS | 66.18 | 81.48 | 71.65 | 72.37 | 83.29 | 73.94 | 72.71 | 85.73 | 83.65 | 74.65 | 86.26 | 84.70 | 76.01 | 85.38 | 85.21 | 78.88 | ||
| UTD | RFNet [1] | 55.98 | 73.35 | 50.86 | 46.39 | 80.04 | 63.04 | 58.69 | 76.43 | 77.52 | 56.65 | 78.50 | 80.07 | 64.72 | 76.86 | 79.89 | 67.93 | |
| mmFormer [2] | 53.47 | 72.29 | 52.91 | 49.46 | 81.13 | 60.50 | 59.18 | 74.66 | 78.45 | 59.60 | 78.50 | 81.81 | 63.73 | 77.74 | 80.53 | 68.26 | ||
| PRISMS | 36.25 | 73.74 | 52.28 | 40.93 | 82.58 | 64.76 | 59.58 | 78.35 | 79.54 | 62.52 | 81.09 | 83.46 | 66.48 | 77.62 | 81.97 | 68.08 | ||
| UTD (+PRISM) | RFNet [1] | 30.42 | 69.15 | 26.40 | 32.13 | 69.52 | 31.47 | 72.24 | 69.90 | 37.48 | 70.18 | 71.35 | 52.87 | |||||
| mmFormer [2] | 29.57 | 70.50 | 27.54 | 31.17 | 72.56 | 37.61 | 35.30 | 67.65 | 70.20 | 30.26 | 70.87 | 70.97 | 36.93 | 69.97 | 70.50 | 52.77 | ||
| PRISMS | 30.71 | 68.90 | 28.61 | 32.29 | 71.12 | 37.93 | 38.02 | 69.41 | 70.85 | 38.46 | 68.54 | 70.64 | 41.37 | 69.35 | 70.28 | 53.77 |
PRISM wurde als Plug-and-Play-Modul entwickelt, das in verschiedene Backbone-Architekturen integriert werden kann, um die Balance zwischen den Modalitäten wiederherzustellen. Zur Validierung dieses Ansatzes wurde PRISM in moderne Methoden zur Segmentierung unvollständiger multimodaler medizinischer Bilder eingebunden und unter verschiedenen Modalitätsausfallraten evaluiert.
Im Vergleich zum vollständigen Trainingsszenario (VTD) zeigt sich, dass bei unvollständigem Training (UTD) – unabhängig vom verwendeten Backbone – eine deutliche Leistungseinbuße auftritt. Der Einsatz von PRISM führt jedoch zu konsistenten Leistungsverbesserungen über verschiedene Subtypen und unter unterschiedlichen Modalitätskombinationen.
Bemerkenswert ist, dass PRISM in der Bewältigung des UTD-Szenarios teilweise sogar bessere Segmentierungsergebnisse erzielt als im VTD-Szenario. Diese Beobachtung belegt die Robustheit und Flexibilität des PRISM-Ansatzes, der es ermöglicht, selbst bei fehlenden oder gestörten Modalitäten optimale Ergebnisse zu erzielen.
Distanzablation
| Distance | DSC [%] ↑ | HD [mm] ↓ | ||||||
|---|---|---|---|---|---|---|---|---|
| WT | TC | ET | Avg. | WT | TC | ET | Avg. | |
| None | 96.32 | 81.29 | 60.24 | 79.28 | 9.91 | 10.90 | 7.28 | 9.36 |
| Dice Loss | 96.29 | 81.45 | 60.20 | 79.31 | 9.76 | 10.01 | 7.29 | 9.02 |
| KL Loss | 96.50 | 81.58 | 60.34 | 79.47 | 9.74 | 9.97 | 7.02 | 8.91 |
| Proto Loss | 96.73 | 82.37 | 60.63 | 79.90 | 9.64 | 10.09 | 6.41 | 9.08 |
| L2-Proto-Distance | 96.91 | 82.18 | 60.95 | 80.00 | 9.38 | 9.28 | 5.90 | 8.00 |
Ein zentrales Element des PRISM-Ansatzes ist die Distanz $D^m_n$ (siehe Abschnitt 2.2). Diese wird als L2-basierte Prototyp-Distanz über alle Klassen definiert und repräsentiert die relative Präferenz des multimodalen Teachers für den jeweiligen unimodalen Pfad $m$. In der obenstehenden Tabelle wurden verschiedene Methoden zur Berechnung von $D^m_n$ evaluiert – darunter der Dice Loss, der KL Loss und der Proto Loss.
Temperatur
| DSC [%] ↑ | HD [mm] ↓ | |||||||
|---|---|---|---|---|---|---|---|---|
| µ | WT | TC | ET | Avg. | WT | TC | ET | Avg. |
| 1 | 83.01 | 69.12 | 51.82 | 67.98 | 14.50 | 13.03 | 8.73 | 12.09 |
| 2 | 83.51 | 70.63 | 51.91 | 68.68 | 12.22 | 12.17 | 8.07 | 10.82 |
| 3 | 83.66 | 70.99 | 52.46 | 69.04 | 11.80 | 10.87 | 8.01 | 10.23 |
| 4 | 83.91 | 71.15 | 52.77 | 69.28 | 12.59 | 13.85 | 8.42 | 11.62 |
| 5 | 82.73 | 69.80 | 52.43 | 68.32 | 14.06 | 12.95 | 9.00 | 12.00 |
| 6 | 83.13 | 69.86 | 52.47 | 68.49 | 12.96 | 12.32 | 7.90 | 11.06 |
| 7 | 82.87 | 70.18 | 51.81 | 68.29 | 13.48 | 12.24 | 8.04 | 11.25 |
| 8 | 83.13 | 70.31 | 52.00 | 68.48 | 12.06 | 11.57 | 7.92 | 10.52 |
| 9 | 83.23 | 70.51 | 52.53 | 68.76 | 11.64 | 11.70 | 7.51 | 10.28 |
| 10 | 83.44 | 70.14 | 52.25 | 68.61 | 12.90 | 11.95 | 7.82 | 10.89 |
| WCE | 80.83 | 70.04 | 52.04 | 67.64 | 20.13 | 15.40 | 9.54 | 15.02 |
| F-L2 | 81.91 | 67.72 | 50.25 | 66.63 | 14.48 | 13.09 | 8.47 | 12.01 |
Die Temperatur $\mu$ in Gl. $L_{\text{pixel}}^m$ ist ein Hyperparameter, der die „Softness“ der Wahrscheinlichkeitsverteilungen steuert. Um den Einfluss von $\mu$ auf die Segmentierung zu untersuchen, werden Ablationsstudien durchgeführt, in denen der Wert von $\mu$ variiert wird. Darüber hinaus validiere ich die vorgeschlagene pixelweise Selbst-Distillation, indem ich den KL-Verlust durch einen gewichteten Kreuzentropie-(WCE-)Verlust mit Ground-Truth sowie einen Feature-wise L2-Verlust (F-L2) als Vergleich ersetzen. Quantitative Ergebnisse sind in Tabelle 2 zusammengefasst. Insgesamt ist es vorteilhafter und stabiler, die pixelweise Selbst-Distillation über den KL-Verlust zu bestrafen, da dieser relativ unempfindlich gegenüber $\mu$ ist. Konkret erzielen die Einstellungen $\tau = 4$ und $\tau = 3$ die beste Dice- und HD-Leistung.
Quellen
[1] Ding, Y. et al. (2021). RFNet: Reinforced Feature Fusion for Medical Image Segmentation. GitHub repository.
[2] Zhang, W. et al. (2022). mmFormer: Multimodal Medical Image Segmentation with Transformer-based Fusion. arXiv preprint arXiv:2206.02425.